 てっぱんITクラブ
てっぱんITクラブ


今回はデータサイエンスとAIについての基本を解説するよ!

最近流行りのAIですか。便利とか怖いとかいろんな話が出回ってますよね~

ぼくは映画はマトリックスが好きなので、AIが暴走して人間に反乱するんじゃないかと怖いがつよいです。

そうだね~。いろんな話があるから難しく感じたり、怖く感じたりすると思うね。
今回はAIやデータの基礎を学ぶことで知らないことで生まれる恐怖ってのはだいぶ薄れると思う。
試験でも流行りだからこそ問われることが増えているからしっかり押さえておこう!
データ活用でできること
データを持つことはチカラに直結するんだ。
敵の配置を知っていれば桶狭間のように少ない兵でも多数の敵に勝てるかもしれない。
昔も今も、データや情報というのは非常に大きな意味を持つ。
昨今ではさらにAIやデータの活用方法によってできることの幅が広がり需要が高まっているんだ。
データがあれば未来予測もでき、天気予報も、地震予測も、次にどんな商品が売れるのかも予測できてしまう。
大量のデータと大量のデータを処理し、活用する技術・AI、人工知能によってデータはさまざまな意味を持つようになった。
ただ、データは集めて単純にAIに学習させればいいというわけではなく、人間が間に入る必要がまだまだあるんだ。
データっていうのはバラバラの形をしていて、これまでの天気データ、地震データですらバラバラの形になっている。
これを整理整頓してAIに学習しやすい形に変更したり、何を目的に学習を進めさせるか、揃ったデータのどの値を見て予測結果とするかなどは人間の力が必要なところなんだ。
データをどう活用するか、大量のデータで何をして行くのかが重要で、そもそも大量のデータを持っていること自体がスタートラインに立つために必要なことになってきているよ。
今回はそんなデータの種類や使い方、AIについて詳しく紹介・解説していく。
データの種類と可視化
データにはどんな種類がある?
まずはデータにはどんな種類があるか!ってところから。
データサイエンスやAIを扱うデータは多種多様なんだ。ここでは主なデータの種類について紹介するよ。
・構造化データと非構造化データ
構造がしっかりと組み込まれデータ同士のつながりがわかりやすく整理されたデータが構造化データ。
データ同士のつながりが曖昧な整理されていないデータが非構造化データだ。
従来はとにかくデータは整理されているべきだという考えが主流だったけど、昨今ではとにかくデータの数を揃えてから、出てきたデータを整理するのはその後という考えが出てきている。
構造をしっかり整理して何のデータと何のデータがつながっているのかを明確にしていた時代が構造化データで少し前の主流。
さまざまなセンサーのデータをとにかく集めた乱雑なデータが非構造化データで、昨今はこっちが多いという形で覚えておこう。
・機械のログと人の行動ログ
機械のログは、機械がどのように動いたかのログで通信履歴やOSへのログイン履歴などが含まれるデータだ。
人の行動ログというのは、どこで電車に乗って、どこでお金を下ろし、何を買ったのかというログだよ。
監視カメラが大量にある世の中では、誰が何をしているのかがすぐにわかるのはこの行動ログが取られているからというわけだね。
人の行動ログを利用することでショッピングの際に何を基準に商品を選んでいるのか、どういった広告を見た人が購入に行き着いたのかが見えるようになりつつあるんだ。
全ての行動ログを取られるのは気持ちがいいものじゃないけど、だんだんとそれが当たり前の時代になりつつあるのも現実だね。
・量的データと質的データ
意味のある単位がつき、計測可能なものを量的データ(定量的データ)、計測する性質がないものを質的データ(定性的データ)と呼ぶ。
量的データの例は、時刻や速度、質量などがあって、質的データは血液型や満足度、会話などがある。
・1次データと2次データ
1次データは出来事を直接記録したもののこと。
2次データは1次データを取捨選択して見やすくしたり目的に合致した説明を行ったりしたものだよ。
2次データはあくまで誰かが加工しているデータだから、1次データの方が信憑性は高いというのが世間一般の見方だ。
ただ1次データが全て信頼できるかと言われるとそうでもない、しっかりとどういった方式で取得されたデータなのかは吟味する必要があるよ。

紹介されているデータの種類はそれぞれペアになっていますが、ペアに何か特別な意味ってあるんですか?

ペアの組み合わせに意味はないよ。
似たようなデータ同士を比較しながら紹介した方がわかりやすいと思ってペアで紹介しているだけだよ。
グラフ、可視化の種類
データは集めただけだと、何のデータなのかいまいちピンとこないと思う。
実際にはデータをいかに見やすくするかの可視化が重要になってくるんだ。
問題解決や意思決定をするためにわかりやすい形で示す必要があるから、グラフの種類は押さえておいた方がいいよ。
ここではQC7つ道具と呼ばれる元々は工場製品の品質を向上させるためのツールだったけど、データの分析や問題解決に広く応用される可視化について紹介する。
・パレート図
データの件数を表す棒グラフとデータの累積比率を表す折れ線グラフを組み合わせた図。
何が重点管理項目かをわかりやすく表現してくれる。
・特性要因図
原因と結果をわかりやすく表すためのグラフ。
両者が矢印によって結ばれ、見た目からフィッシュボーン図と呼ばれることもある。
・散布図
2つの物事の関係を表すためのグラフ。
関係は三つに分類することができる。
正の相関、負の相関、相関がない
・ヒストグラム
どの段階にどのくらいの人やものが存在しているかを視覚的に表現するグラフ。
「ある階級に属するデータの個数(頻度)」「データのばらつきの度合い(分散)」がわかる。
・チェックシート
作業漏れを防ぐための確認表。
作業が完了するごとにマークを記入して、うっかりミスを防止する。

・層別
グラフではなく、データを属性ごとに分けよう。という考え方の図。
データの特徴を掴みやすくなるよ。

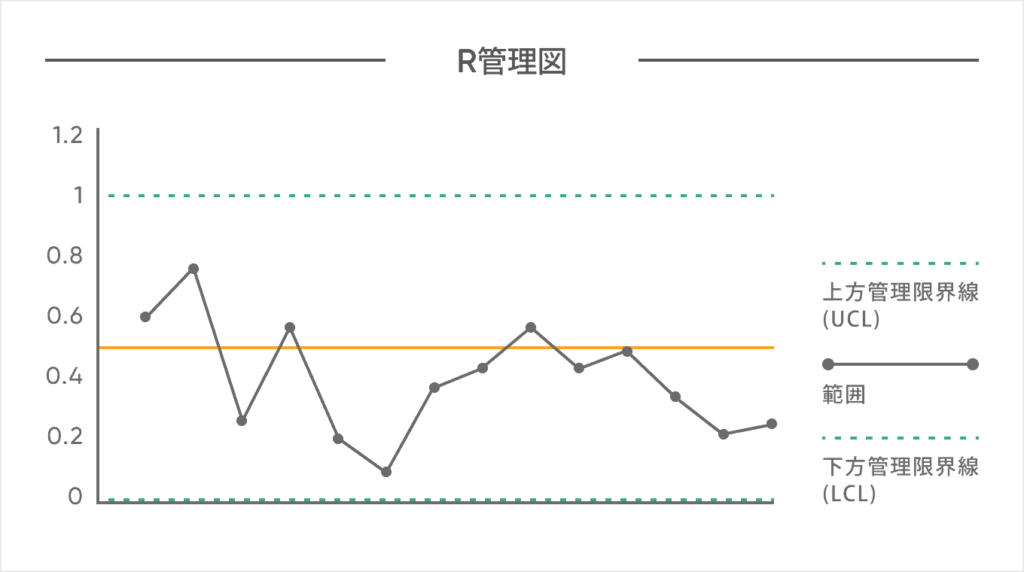
・管理図
データの中から「出たらまずい!」というデータを早期発見するためのグラフだ。
限界値という横線を上下ともにオーバーしないことを監視するためのグラフだね。
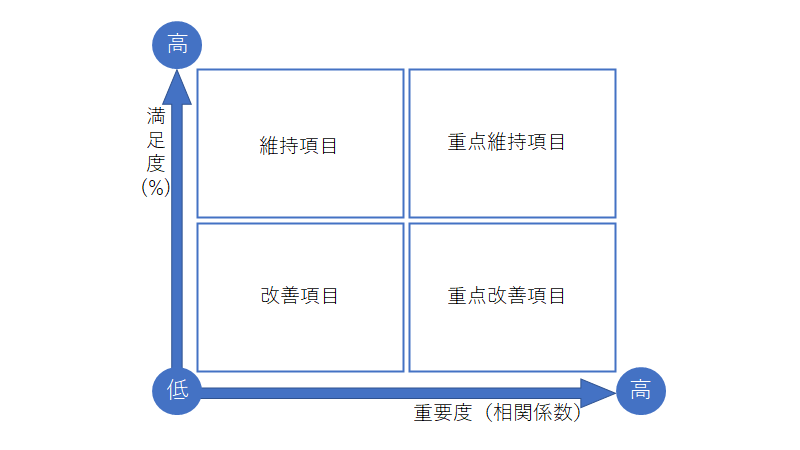
・ポートフォリオ図
厳密にはQC7つ道具ではないものの、よく使われるのがポートフォリオ図だ。
ある評価軸における何かの位置付けと、その大きさを同時に表現できるグラフ。
全部の名前と仕組みを覚える必要はないけど、可視化名を言われたら何となくこんなグラフだろうな~という想像ができるくらいは理解しておこう。
データを使う統計手法
データを扱う上で重要なのが統計の知識だよ。
大量のデータの特徴を捉え、どういったデータ的特徴があるのかを知る手段が統計なんだ。
一般的な統計用語
まずは統計でよく使われる用語について解説していくよ。
・平均値
データ全体を足して、データ数で割ることで算出できる平均値。
データ全体の大体の傾向を掴むことができる値だ。
・中央値
データを大きさ順に並べた時の真ん中の値が中央値だ。
100点、30点、5点のテストがあった時、中央値は30点となる。
データが偶数個の場合は、二つの中央値を足して2で割ることで算出するよ。
100点、40点、10点、3点の場合、(40+10)÷2 = 25が中央値になる。
・最頻値
データの中で一番たくさん出てくる値のことだよ。
大好物は何ですか?結果:ハンバーグ50人、カレーライス30人、うどん100人という場合に100人が最頻値となる。
・標準偏差
データのばらつきの度合いを表す数値だ。
値が大きいほどデータがばらついている。0だとばらつきがないみんな同じデータであることを示すよ。
平均値からどれだけ外れた値があるのかを確認することができる値だ。
データマイニング
ここまで紹介した統計手法では貴重なデータの有効性を確認することができず、あくまでデータの特徴を知るまでにとどまっていた。
データマイニングはデータの特徴から傾向を発見できるんだ。
データマイニングで一番有名な分析手法が「連関規則」というものだよ。
連関規則はAだからBというデータ二つについての関係性を見出す分析手法だ。
例えば「風が吹く」から「桶屋が儲かる」という連関規則がある。
データから見つかったルールのことを連関規則というわけだ。必ずしも明確な理由があるというよりかはデータを見たところ傾向として「風が吹く」から「桶屋が儲かる」があるというのがわかる感じだよ。
さらに逆は成立しにくいことも知っておこう。
「桶屋が儲かる」から「風がふく」とは一般的には言えない。
データもあくまでも風が吹くという条件があると桶屋が儲かるというデータ的特徴しか見出せていない点は注意が必要だよ。

で、データに特徴を見出すのは人間がやっているのがデータマイニングっていうことでしょうか?
その認識で間違いないよ。
次から説明するAIっていうのはその傾向やルールっていうのを独自に見つけていく手法という感じになるよ。
AIとは
AIとは、人工知能(Artificial Intelligence)の略称だ。
一般的には、機械やソフトウェアが人間のように学習、推論、問題解決、知覚、言語理解などの知的行動を行う能力を指すよ。
AIは大きく分けて二つのカテゴリに分類されて「弱いAI」と「強いAI」だ。
「弱いAI」とは、特定のタスクを遂行するために設計されたAIで、囲碁やチェスで優秀な成績を収めるものの地球温暖化などの別カテゴリーには全く意味をなさないAIなどのこと。
「強いAI」とは、人の精神活動を代替したり、人間の知性と同じようにさまざまな問題を解決できる能力を持つAIのことだ。
日常会話で出てくるAIというのは基本弱いAIを指していると思ってくれて問題ない。
AIには得意と不得意があって、大量のデータを元に推論を導くことは得意。
データが少なく合理的な推論ができない状況下での判断や、複数の分野にまたがる仕事というのは不得意としているよ。
AIをどう使うかが昨今では非常に重要になってきている。
AIをツールとしてどう活かすのかが人間の腕の見せ所だね!
AIで使われる技術の解説
AIが実際にどのように学習を進め推論をするのかについて解説していくよ。
機械学習
データからルールを見つけてアルゴリズムにするのがこれまで人間がやってきたことだけど、機械学習ではデータからルールを見つけてアルゴリズムに変える部分を機械自身ができるようになるんだ。
アルゴリズムが自動的に最適なものになっていくのが学習というわけだ。
機械学習の中にも種類があって、教師あり学習、教師なし学習っていうのが代表的なところだね。
教師あり学習とは学習するデータに答えがあって、答えを確認しながら学習していく方式。
教師なし学習は学習するデータに答えない状態で、法則性や規則性をプログラム自ら探していく方式だ。
教師あり学習は問題集を配って問題を解いて答え合わせをして、試験対策をしていく感じ。
教師なし学習はよくわからない問題集(答えなし)をもらって、何となく何の資格であるかを推測できるようにする感じ。
きょ、教師なし学習って使い道あんまりなさそうなんですが、どこかで使えたりするんですか?

教師なし学習は分類とかに力を発揮することが多いよ。
画像認識で犬という分類をするとき、犬はこれだよ!っていう答えを示さなくても大量の写真データから自動的に犬を分類できるようにすることができるんだ。
教師あり学習は学習のイメージがつきやすいけどそもそも大量のデータに答えをつけるっていう作業が人間の手でやる必要があるから、大変だったりもするんだ。
ディープラーニング
機械学習の方法の一つでもあるディープラーニングは昨今注目を集めているんだ。
人間の脳が情報を処理する方法に似ている学習方法で、ニューロンという細胞がたくさんあってニューロン同士がつながったネットワークを用いる。
ニューロン一つ一つが少しだけ処理を実行して、次のニューロンに渡すことで情報が伝搬されて答えに行き着くという仕組みで、ニューロン一つ一つが少しずつ答えを導くために進化していく手法なんだ。
ディープラーニングを詳しく解説すると、1日かかるから今回は、機械学習の一つで最近のAIの主流、脳の構造に近い学習方法であるってことだけ押さえておけば大丈夫!
まとめ

今回はデータサイエンスの基本とAIについて解説してきたわけだけど
どうだったかな?

中学生くらいの時やった統計は懐かしいって感じで、AIについては何となくしかわからなかったですね。

ぼ、ぼくはもっとディープラーニングを知りたいって思いました。
ITパスポートではそこまで深く機械学習の部分は問われずサラッと流すくらいで大丈夫だよ。
ディープラーニングについてもっと詳しく知りたい場合はこっちの資料も見るといいかもしれない。
じゃあ、今回はここまで、また次回!!

はい!ありがとうございました!!

